
Reduce document processing time by up to 90% with AI-based document classification.
A practical use case for TPAs.
The Real Bottleneck No One Talks About
Most people think claim delays happen during approvals. They don’t. They start much earlier, at document sorting.
A typical health insurance claim comes in as:
- A 30–80 page PDF or more
- Mixed documents: bills, lab reports, prescriptions, discharge summary
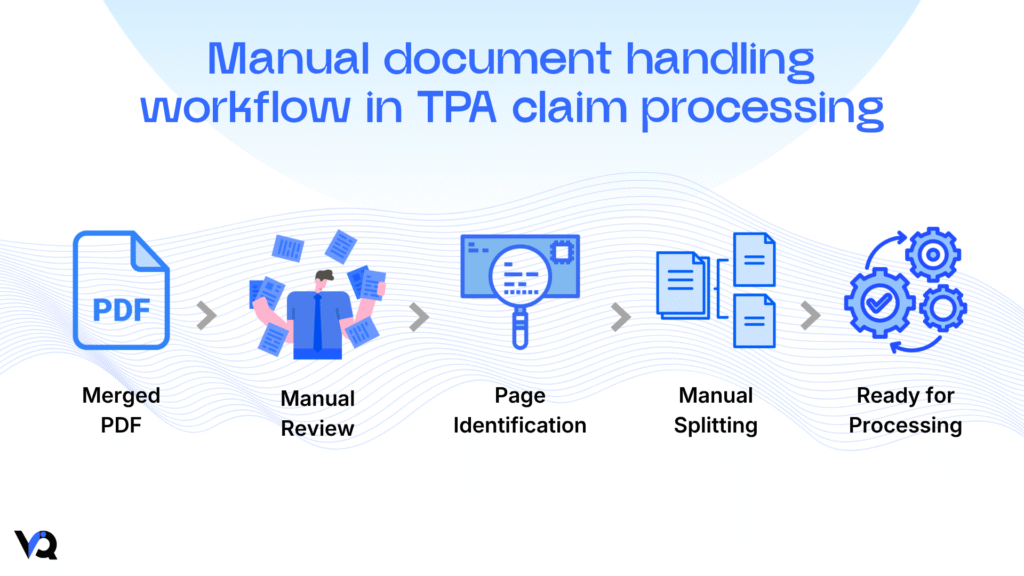
Before any actual claim processing begins, someone has to:
- Scroll through every page
- Identify what each page is
- Split them into separate documents
It’s manual. It’s repetitive. And at scale, it slows everything down.
Why This Becomes a Big Problem for TPAs
If you’re processing hundreds or thousands of claims daily, this step alone creates:
- Delays before claim evaluation even starts
- Errors when documents are misclassified
- Inconsistency depending on who is doing the work
- Operational overhead that doesn’t scale
And the biggest issue? Every hospital formats documents differently.
A Simple Example
Take a standard claim:
- 65-page merged PDF
- Includes bills, reports, prescriptions
Without automation: ~10–15 minutes just to sort documents
With AI: Classification and splitting happening in seconds
That’s where AI in health insurance claims starts making a real difference.

Why Rule-Based Systems Don’t Work
A common attempt at automation is using rules like:
- “If page contains ‘Discharge Summary’, classify it”
- “If page has ‘Total Amount’, it’s a bill”
Sounds logical, but breaks quickly.
Because in reality:
- Hospitals don’t follow standard formats
- Headings change
- Some documents don’t even have clear labels
- Layouts vary wildly
So these systems:
- Need constant updates
- Still make mistakes
- Don’t scale
What Actually Works: AI-Based Document Classification
Instead of trying to match keywords, AI looks at the entire page.
Not just the text, but also:
- Layout
- Structure
- Visual patterns
This is what makes it reliable across different hospital formats.
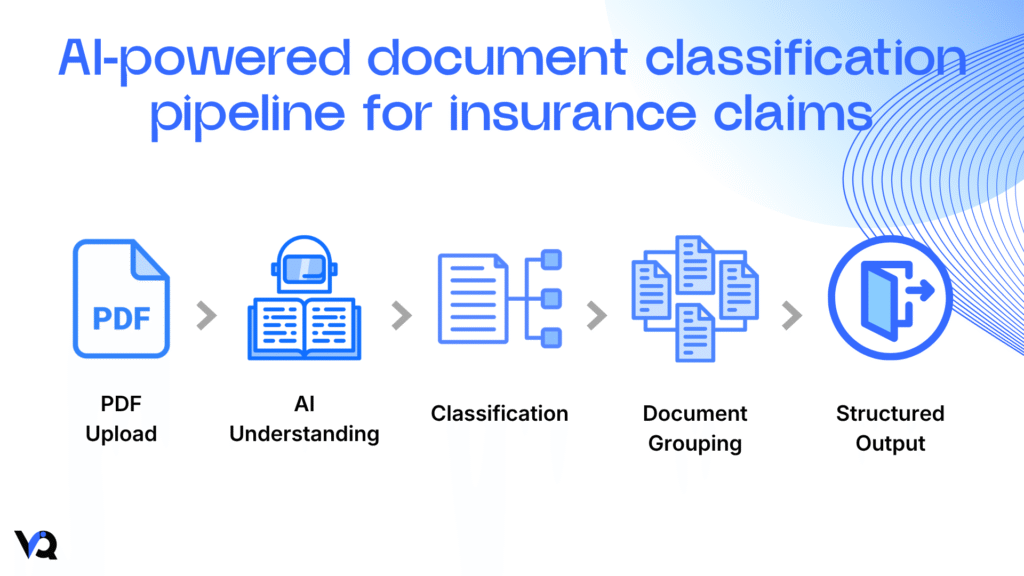
At a high level, the system:
- Breaks the PDF into pages
- Understands each page (text + layout)
- Labels it (bill, report, summary, etc.)
- Groups and splits documents automatically
That’s it.
No rules. No manual effort.
How the System Works (Simplified)
Here’s what’s happening under the hood, without getting too heavy:
Step 1: Split the Document
The PDF is broken into individual pages.
Step 2: Understand Each Page
AI models analyze:
- Structure (tables, headers)
- Content distribution
- Visual layout
Step 3: Classify
Each page is tagged:
- Discharge Summary
- Pharmacy Bill
- Lab Report
- Prescription
Step 4: Reassemble
Pages are grouped and split into clean documents.
Example:
- Pages 1–5 → Discharge Summary
- Pages 6–18 → Bill
- Pages 19–30 → Lab Reports
Why This Approach Works Better
The key shift is simple: From rules → to understanding
This means:
- Works across different hospital formats
- Doesn’t rely on keywords
- Improves over time
- Requires minimal maintenance
And most importantly, it scales.
What This Means for TPA Operations
This isn’t just a small improvement. It directly impacts TPA claim processing efficiency.
- Faster Start to Claims: Up to 70–90% reduction in document prep time
- Fewer Errors: Better classification leads to fewer downstream issues
- Lower Manual Work: Less dependency on operations teams
- Higher Throughput: More claims processed without increasing headcount
Why This Step Matters More Than It Looks
Document classification is the first step in the claims pipeline.
If this step is slow or wrong:
- Data extraction gets messy
- Policy validation is delayed
- Claim decisions take longer
Fix this and everything downstream improves.
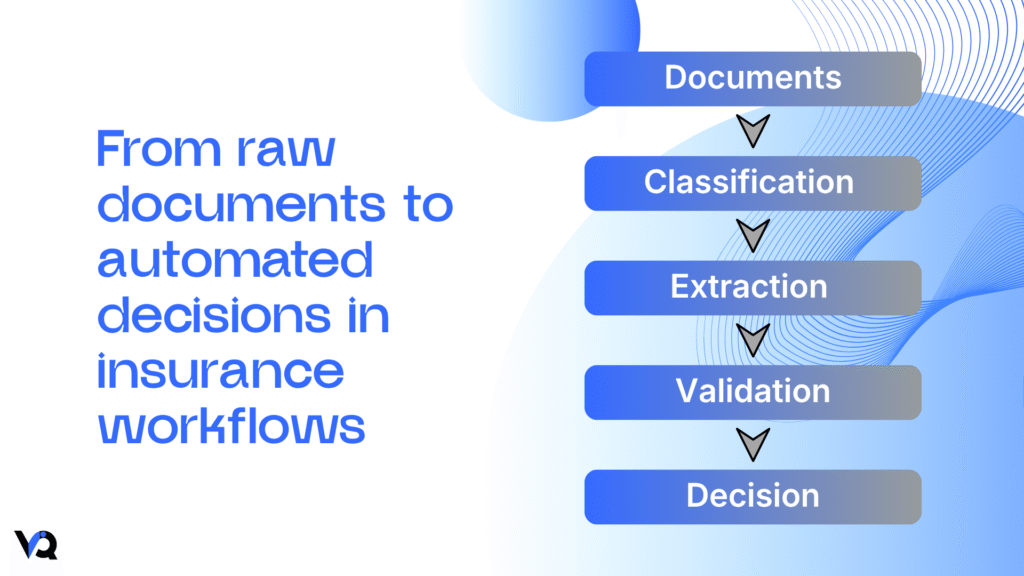
The Bigger Picture
Once documents are structured, you unlock:
- Automated data extraction
- Policy validation using AI
- Fraud detection
- Faster claim decisions
In simple terms: Documents → Data → Decisions
How This Is Being Built in Practice
At VantageIQ Technologies, this isn’t treated as a standalone feature.
It’s part of a broader document intelligence system that combines:
- OCR + layout understanding
- Transformer-based models
- API integrations with claim systems
- Confidence-based validation workflows
The focus is not just accuracy, but making it production-ready and scalable.
Final Thought
If you’re looking at insurance claim automation, this is one of the most practical places to start.
It solves a real problem.
It delivers immediate impact.
And it sets up everything that comes next.
For TPAs, this isn’t optional anymore, it’s becoming foundational.