
Everyone is chasing the AI dream. CTOs are under intense pressure to deploy the latest Large Language Models (LLMs). Data teams are racing to build custom generative AI solutions. The hype makes it look easy: plug in a model, and watch your business transform.
But behind closed doors, a frustrating reality is setting in. Many enterprise AI pilots are stalling. Models hallucinate. Systems run up massive cloud bills. Outputs lack business context.
Why is this happening? Because organizations are focusing on the brain (the AI model) while ignoring the circulatory system (data engineering).
At VantageIQ Technologies, we see this shifting landscape daily. The truth is becoming clear. In 2026, robust data engineering is far more critical to business success than the complexity of your AI models.
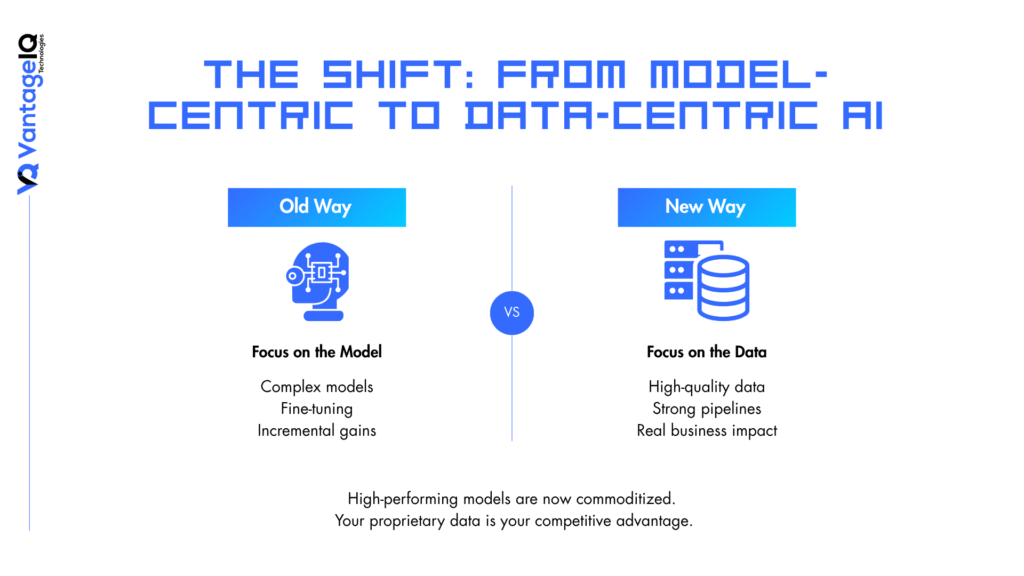
The Shift from Model-Centric to Data-Centric AI
For years, the tech world focused on model design. Data scientists spent months tweaking algorithms to improve accuracy by fractions of a percent.
Today, that game has changed. High-performing foundational models are now commoditized. You can access world-class AI via a simple API call. The core differentiator for your enterprise is no longer the model itself. It is your proprietary data.
If you feed a brilliant model fractured, dirty, or delayed data, you will get poor results. AI leaders call this “garbage in, garbage out.” To win at enterprise AI, leadership must pivot from model-centric development to data-centric infrastructure.
Why AI Models Are Failing in Production
Building an AI prototype is simple. Scaling it to production is incredibly hard. When enterprise AI initiatives stall, the root cause is rarely the model.
Here is what actually goes wrong:
- Context Blindness: Models do not know your business. Without secure, real-time access to your internal data warehouses and customer databases, their utility is heavily limited.
- Data Silos: Your customer data lives in Salesforce. Your financial data lives in SAP. Your operational data sits in a legacy cloud bucket. An AI model cannot bridge these gaps on its own.
- Latent Pipelines: A customer service AI agent needs today’s data, not last week’s batch update. Outdated data pipelines cause models to make decisions based on stale facts.
Without solid data engineering, your AI investments remain expensive science experiments.

The Quiet Heroes: Where Data Engineering Saves the Day
Data engineering is the foundational layer that makes AI usable, safe, and cost-effective. Here is how modern data pipelines rescue failing AI strategies:
1. Powering Advanced RAG Frameworks
Retrieval-Augmented Generation (RAG) is the gold standard for enterprise AI. Instead of retraining massive models, RAG fetches relevant internal documents and hands them to the AI to answer specific queries. But RAG is entirely a data engineering challenge. It requires setting up vector databases, parsing unstructured PDFs, and maintaining real-time data syncs.
2. Cleaning Data at Scale
AI models are highly sensitive to bias and noise. Data engineers build automated validation pipelines. They deduplicate records, fix formatting errors, and strip out sensitive Personal Identifiable Information (PII) before the data ever touches an AI model.
3. Optimizing Cloud and Compute Costs
Running enterprise AI is expensive. Unoptimized data pipelines send massive, redundant datasets into LLMs, skyrocketing your token costs. Data engineers design smart data fabrics and semantic layers. They ensure the AI only processes the exact data it needs, keeping your cloud budget under control.

What This Means for CTOs and Data Leaders
If you are leading a digital transformation, it is time to reallocate your focus and budget. Here is how to realign your strategy:
- Balance Your Hiring: Stop hiring only specialized prompt engineers or niche data scientists. Double down on data engineers who understand Apache Kafka, Snowflake, dbt, and cloud-native architectures.
- Invest in Architecture Over Fine-Tuning: Do not waste resources fine-tuning a 70-billion parameter model from scratch. Spend that capital building a robust data mesh or a unified lakehouse architecture.
- Focus on Data Governance: Ensure your data engineering pipelines include strict lineage tracking. You must know exactly where your data comes from, who cleaned it, and how it reaches your AI applications.

Build Your AI Foundation
The verdict is in. A mediocre model supported by elite data engineering will consistently outperform a brilliant model hamstrung by poor data.
At VantageIQ Technologies, we help enterprises move past the pilot phase. We architect high-performance data pipelines, build scalable data lakehouses, and design secure enterprise AI frameworks that drive actual ROI.
Stop fighting with fragile AI prototypes. Let’s build the data infrastructure your business deserves.
Ready to transform your data into a strategic AI asset? Connect with the VantageIQ team today.