
Data Parser: A reusable enterprise AI accelerator that helps organizations extract, validate, and structure document data, reducing manual effort and accelerating downstream business processes.
Helping organizations transform complex documents into accurate, validated, and usable enterprise data.
Invoices. Claims. Contracts. Applications. Shipping records. Patient forms.
Every organization receives information through documents. Much of that information eventually needs to reach an ERP, CRM, claims platform, electronic health record, analytics system, or operational workflow.
Getting it there remains surprisingly difficult.
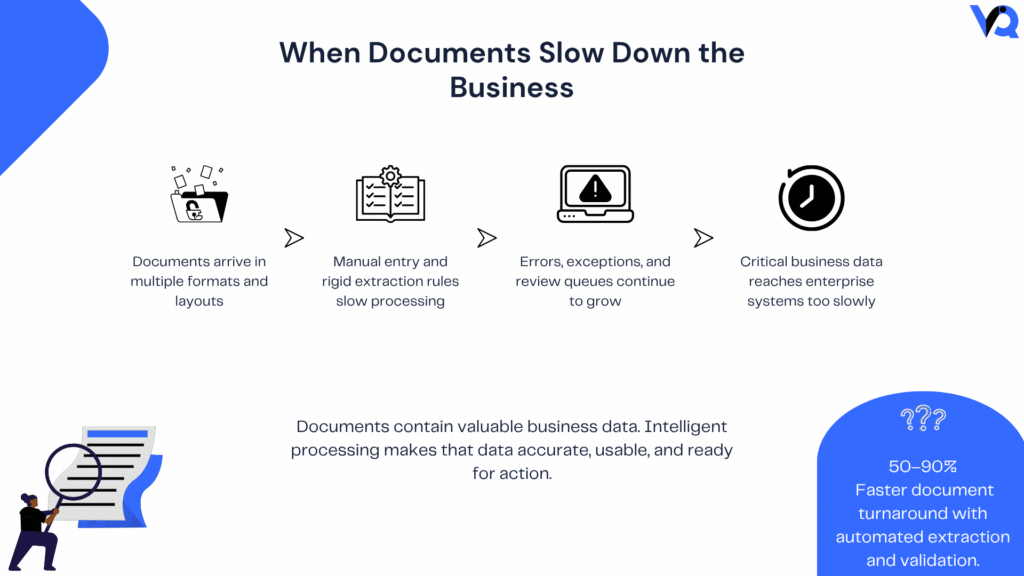
Documents arrive as PDFs, scans, images, emails, forms, and spreadsheets. Their layouts vary. Tables move. Labels change. Some files are incomplete or difficult to read. Traditional extraction methods often depend on fixed templates, while employees manually rekey information when automation fails.
The result is slower processing, recurring errors, growing review queues, and valuable employee time spent moving data between documents and systems.
Enterprise document processing becomes far more valuable when documents can be converted into reliable, structured data that downstream systems can use immediately.
When Documents Slow Down the Business
Document-heavy processes sit at the heart of many critical operations.
Finance teams process invoices and purchase orders. Insurers review claims and applications. Healthcare organizations digitize patient forms. Logistics teams handle shipping and customs records. Legal teams search large contract repositories.
As volumes increase, manual processing becomes harder to scale.
The shift toward intelligent document processing reflects this pressure. Market research estimates the global IDP market at $3.22 billion in 2025, with strong growth expected as organizations invest in automation across finance, healthcare, and government.
Real-world implementations also show the scale of the opportunity. A Microsoft customer example describes an automated finance workflow processing 400,000 invoices and five million receipts each month, while saving 30,000 hours of manual work.
The strategic opportunity extends beyond faster data entry. Structured document data can accelerate decisions, trigger workflows, improve reporting, and make information available across the enterprise.
Moving Beyond Traditional OCR
Data Parser is a reusable enterprise AI accelerator that helps organizations build intelligent document processing capabilities without designing every extraction workflow from scratch.
The accelerator provides reusable foundations for document ingestion, content and layout understanding, field extraction, data normalization, validation, human review, system integration, and auditability.
This approach goes beyond reading text from a page. Modern document processing needs to identify document structure, understand tables and fields, classify information, validate uncertain results, and deliver usable data to downstream systems. IBM similarly describes intelligent document processing as the combination of document classification, data extraction, and workflow integration.
Within VantageIQ‘s Processing Engine layer, Data Parser provides the reusable architecture needed to adapt these capabilities across document types, industries, and enterprise workflows.
From Raw Documents to Enterprise-Ready Data
Data Parser provides a reusable foundation for turning unstructured content into validated business data.
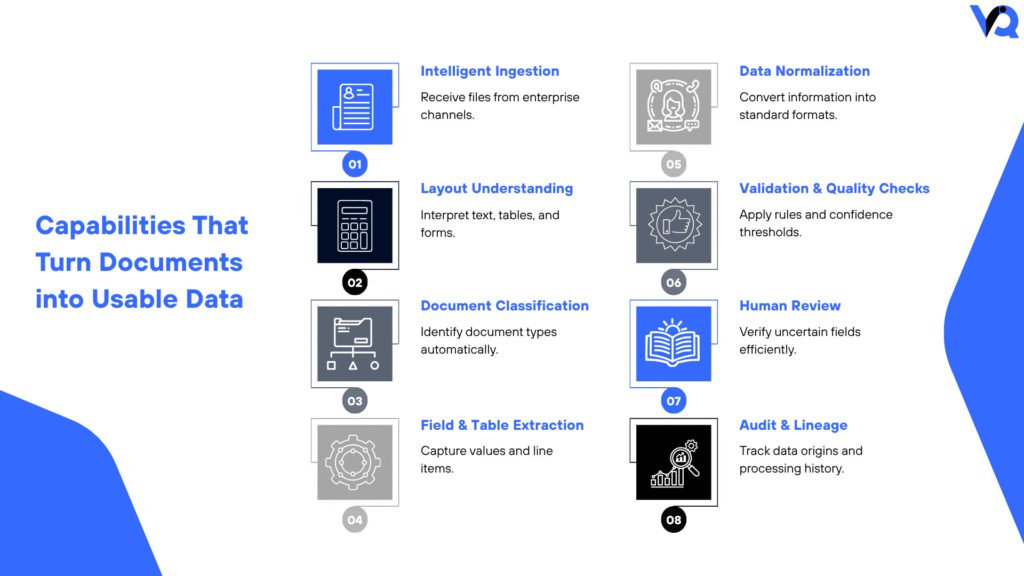
Capabilities That Turn Documents into Usable Data
- Intelligent Ingestion — Receive documents from enterprise channels.
- Layout Understanding — Interpret text, tables, forms, and structure.
- Document Classification — Identify document types automatically.
- Field & Table Extraction — Capture entities, values, and line items.
- Data Normalization — Convert extracted information into standard formats.
- Validation & Quality Checks — Apply rules and confidence thresholds.
- Human Review — Route uncertain fields for targeted verification.
- Audit & Lineage — Track processing history and data origins.
Human review remains especially important for complex enterprise processes. High-confidence information can move forward automatically, while uncertain fields can be sent to the right reviewer instead of forcing every document through the same manual queue.
Where Structured Document Data Creates Business Value
Because documents support almost every business function, the same reusable foundation can enable many different applications.
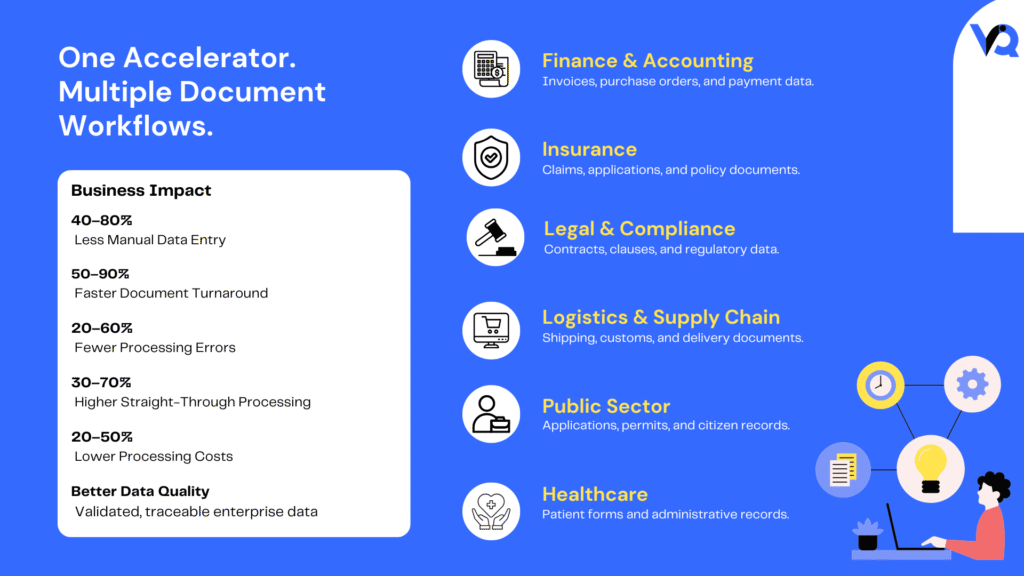
Finance & Accounting
Extract vendor details, line items, tax amounts, payment terms, and due dates from invoices and purchase orders.
Insurance
Process claims, applications, supporting evidence, and policy documents while routing incomplete or uncertain cases for review.
Healthcare
Convert patient forms, lab requisitions, and administrative documents into structured data for downstream systems.
Legal & Compliance
Extract parties, dates, obligations, clauses, and other metadata from large contract and regulatory repositories.
Logistics & Supply Chain
Process bills of lading, customs forms, delivery records, and shipping documents faster.
Public Sector
Digitize applications, citizen forms, permits, and administrative records to reduce manual processing queues.
The Measurable Outcomes
Organizations implementing intelligent document processing typically focus on reducing manual work while improving speed, accuracy, and throughput.
Typical outcomes include:
Metric | Typical Improvement |
Manual data entry | 40–80% reduction |
Document turnaround time | 50–90% faster |
Rekeying and processing errors | 20–60% reduction |
Straight-through processing | 30–70% increase |
Operational processing cost | 20–50% reduction |
Actual results depend on document quality, process complexity, validation requirements, and integration readiness. The broader value comes from creating structured data that can immediately support automation, analytics, and decision-making
Industries Built Around Document-Heavy Workflows
Data Parser is particularly valuable in:
- Financial Services — Invoices, applications, statements, and financial records.
- Insurance — Claims, policies, and supporting evidence.
- Healthcare — Patient forms and administrative records.
- Legal Services — Contracts, case files, and regulatory documents.
- Logistics — Shipping, customs, and delivery documentation.
- Government — Applications, permits, and citizen records.
Turning Document Processing into an Enterprise Advantage
Documents will continue to remain central to enterprise operations. The opportunity lies in reducing the manual effort required to make their information usable.
Data Parser provides the reusable foundation for building that capability faster. By combining document understanding, structured extraction, validation, human review, and enterprise integration, organizations can turn complex documents into reliable data that moves directly into business processes.
As automation expands across the enterprise, the ability to convert unstructured information into trusted, usable data will become a foundational capability for faster operations and better decisions.
Related Accelerators
- Digital Typist
- Smart Router
- Cross-Checker