
Why OCR alone fails, and how AI turns claim documents into structured data.
The Hidden Work After Documents Are Sorted
Sorting claim documents is just the beginning. The real effort starts right after. Every claim still needs someone to go through documents and extract details like:
- Patient information
- Admission and discharge dates
- Procedure codes
- Line-item costs
This is where most of the manual effort actually sits in health insurance claim processing. And unlike sorting, this step is harder to standardize.
If you’re processing hundreds or thousands of claims daily, this step alone creates:
- Delays before claim evaluation even starts
- Errors when documents are misclassified
- Inconsistency depending on who is doing the work
- Operational overhead that doesn’t scale
And the biggest issue? Every hospital formats documents differently.
Where Things Break in Real Workflows
On paper, extracting data from documents sounds simple. In reality, it looks like this:
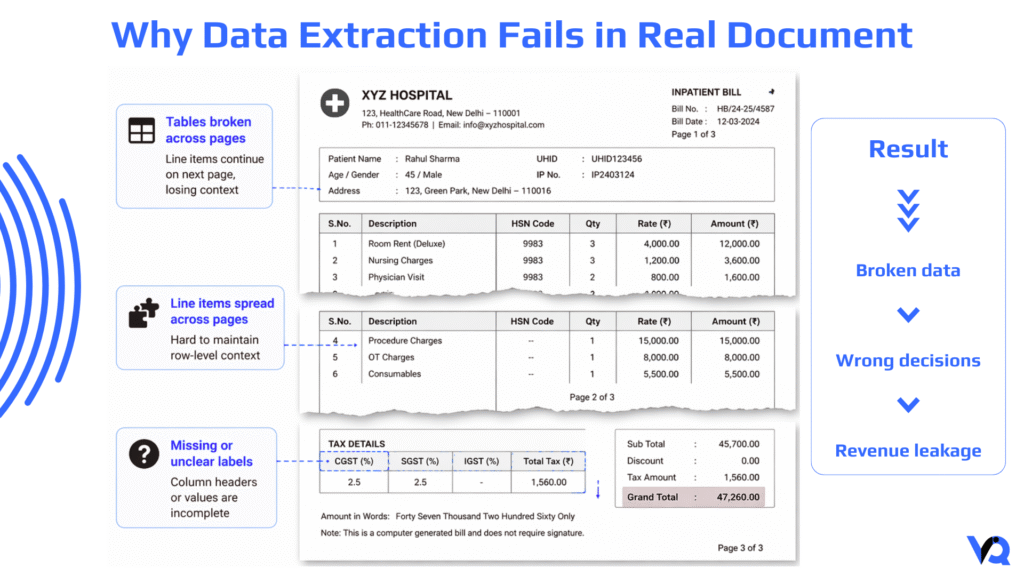
- A hospital bill with multiple tables
- Line items spread across pages
- Inconsistent column formats
- Missing or unclear labels
Even experienced teams struggle to:
- Maintain consistency
- Avoid data entry errors
- Keep up with volume
The problem is not just effort, it’s variability.
Why OCR Doesn’t Solve the Problem
Most automation efforts start with OCR. It’s a logical first step. OCR can read text from documents and convert it into machine-readable form.
But here’s the gap:
OCR extracts text, not meaning.
It can detect:
- Numbers
- Words
- Symbols
But it cannot reliably answer:
- Is this the total bill or a line item?
- Is this a procedure code or a reference number?
- Does this table represent billing or lab data?
When documents vary across hospitals, this limitation becomes even more obvious.

What Actually Changes the Game
To make data extraction work at scale, systems need to go beyond text recognition.
They need to:
- Understand document structure
- Identify what each piece of data represents
- Convert it into usable formats
This is where AI-driven extraction comes in. Instead of reading documents line by line, the system interprets them as structured information.
How Modern Systems Approach Data Extraction
Rather than a rigid pipeline, modern systems treat documents as a combination of layout + language.
Understanding the layout
The first step is reconstructing how the document is organized. Using OCR combined with layout analysis, the system:
- Detects tables
- Identifies rows and columns
- Preserves relationships between values
This is critical for documents like hospital bills, where meaning depends on structure.
Identifying key entities
Once the structure is understood, AI models scan the content to identify important fields. These typically include:
- Patient details
- Dates (admission, discharge)
- Financial values
- Medical codes
This is done using techniques like:
- Named Entity Recognition (NER)
- Domain-trained models for healthcare and insurance
In practice, models trained on real claim data significantly improve accuracy compared to generic models.
Converting into structured data
Finally, everything is mapped into a structured format that systems can use. Instead of raw text, you get:
- Clean fields
- Standardized formats
- System-ready data
For example:
- “Rahul Sharma” → Patient_Name
- “12-03-2024” → Admission_Date
- “₹45,000” → Total_Amount
At this point, the data is no longer tied to the document—it becomes part of the workflow.

What This Looks Like in real-world terms
Take a typical claim:
- 8-page hospital bill
- Multiple line items
- Mixed formatting
Without automation:
- Data entry takes several minutes
- Errors creep in
- Output depends on the operator
With AI:
- Data is extracted instantly
- Tables are preserved
- Output is consistent every time
The difference is not just speed, it’s reliability.

The Real Impact on TPA Operations
This is where the shift becomes meaningful.
- Speed – Data extraction moves from minutes to seconds
- Accuracy – Standardized outputs reduce downstream errors
- Efficiency – Teams are freed from repetitive entry work
- Scale – Processing volume increases without adding headcount
For large TPAs, even small time savings per claim translate into massive operational gains over time.
Why This Step Matters
Data extraction sits right in the middle of the claims pipeline.
If it’s slow or inaccurate:
- Validation gets delayed
- Decisions become unreliable
- Rework increases
Fixing this step ensures that everything downstream works smoothly.
Connecting the Dots
When combined with document classification, the system starts to come together:
- Documents are organized
- Data is extracted
- Inputs become structured
From there, more advanced capabilities become possible:
- Policy validation
- Fraud detection
- Automated decisioning
In simple terms:
Documents → Data → Decisions
How This Is Being Developed in Practice
At VantageIQ Technologies, data extraction is designed as part of a larger document intelligence system rather than a standalone feature.
The focus is on:
- Combining OCR with multimodal LLM
- Using AI models trained on real-world data
- Building flexible pipelines that adapt to different document formats
- Delivering outputs that integrate directly into operational systems
The goal is not just automation, it’s making the data usable at scale.
Final Perspective
If document classification organizes the input, data extraction makes it actionable.
It turns unstructured documents into structured data. It removes one of the most repetitive tasks in claim processing. And it enables faster, more reliable decisions. For organizations investing in health insurance claim automation, this is quickly becoming a baseline capability.
Not a future upgrade, but a present requirement.