
Ensuring secure, compliant handling of PII and PHI in claims processing
When Data Becomes a Liability
In insurance workflows, documents move quickly, between teams, systems, and external stakeholders.
But hidden within these documents is something far more sensitive than billing data. Patient names, phone numbers, addresses, and even detailed medical conditions are routinely embedded across claim files.
As this data flows across multiple touchpoints, the risk is no longer just operational.
It becomes a question of who can access what and whether they should.

For years, the focus in claims processing was efficiency, how quickly documents could be sorted, extracted, and validated.
Today, that’s only part of the equation. Regulations like HIPAA, GDPR, and India’s DPDP Act have redefined expectations. Sensitive data must now be protected, controlled, and minimized by design.
For TPAs and insurers, this translates into:
- Restricted sharing of full claim documents
- Mandatory redaction of sensitive fields before external access
- Controlled and traceable handling of personal data
Manual processes struggle to meet these expectations at scale.
Why Traditional Redaction Falls Short
At a glance, masking data seems straightforward, cover the text and move on. In practice, it often leads to gaps.
Common issues include:
- Sensitive fields missed during manual review
- Inconsistent masking across documents
- Redactions that are only visual, leaving underlying text extractable
The result is a system that appears secure but still exposes risk.

Not All Sensitive Data Looks the Same
One of the biggest challenges in PII/PHI redaction in insurance claims is variability.
Some data follows predictable formats, while other information depends entirely on context.
Structured data (pattern-based detection)
- Aadhaar, PAN, and other ID numbers
- Phone numbers and account details
Contextual data (AI-based detection)
- Patient and doctor names
- Diagnoses and medical conditions
- References embedded within free text
Handling both requires more than rules, it requires contextual understanding.
How AI-Based Data Masking Works
Modern systems approach this problem using a layered detection strategy.
First, pattern-based techniques identify structured data quickly and with high precision. This ensures that standardized fields like IDs and phone numbers are reliably detected.
Next, AI models trained on healthcare and language data analyze the surrounding text to identify contextual entities such as names and diagnoses, even when formats vary or wording is inconsistent.
Together, these layers ensure:
- High precision for structured data
- Deep coverage for contextual information
- Consistent detection across documents
This combination enables scalable AI in insurance data security.

From Detection to True Redaction
Detecting sensitive data is only half the solution. What matters more is how securely that data is handled.
Once identified, the system:
- Maps each entity to its exact location in the document
- Applies secure masking overlays
- Generates a sanitized version for safe sharing
Unlike basic tools, this process ensures that the original data cannot be recovered. It is the difference between hiding data and protecting it.
What Changes in Real Workflows
This approach simplifies document handling significantly.
Instead of manual review, the process becomes:
- Upload the document
- Automatically detect sensitive fields
- Apply masking in real time
- Generate a secure version instantly
This leads to faster processing times, reduced manual effort, and consistent outputs across claims.
Why This Matters for TPAs and Insurers
This capability directly impacts both compliance and operational efficiency.
AI-based data masking helps organizations:
- Stay compliant with HIPAA, GDPR, and DPDP regulations
- Prevent unauthorized exposure of sensitive data
- Reduce manual effort in document sanitization
- Build trust with auditors, partners, and customers
In a data-sensitive ecosystem, trust becomes a competitive advantage.
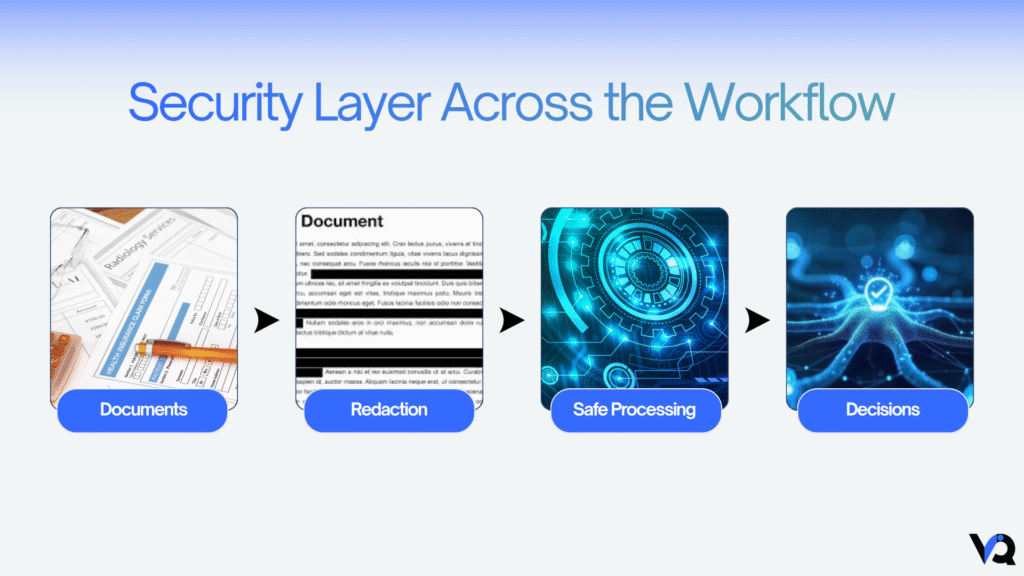
Where This Fits in the Claims Lifecycle
Data masking acts as a protective layer across the entire claims workflow.
Before documents are processed, shared, or stored, they are first sanitized. This ensures that downstream systems only interact with secure, compliant data.
Documents → Secure Redaction → Processing → Decisions
How This Is Being Built in Practice
At VantageIQ Technologies, data masking is integrated directly into the document intelligence pipeline.
The system combines:
- Pattern-based detection for structured data
- AI-driven contextual recognition
- Coordinate-based mapping for precision
- Secure rendering to ensure irreversible masking
The focus is not just automation, but ensuring consistent and scalable protection of sensitive data.
Closing Perspective
As insurance workflows become more digital and interconnected, the volume of sensitive data continues to grow.
Efficiency alone is no longer enough. Systems must be designed to protect data at every stage.
AI-powered PII and PHI redaction ensures that organizations are not just faster, but more secure, compliant, and trustworthy in how they handle information.